BASH скрипт резервного копирования WEB сервера
Раздел(ы): Резервное копирование
Просмотры: 8381
Комментарии: 0
Резервное копирование должно быть таким, чтобы Вы в любой момент могли сменить хостера и переехать на новый сервер. Поэтому весь процесс создания архивов должен быть автоматизирован. А файлы бэкапов должны лежать в надежном месте с возможностью круглосуточного доступа из любой точки планеты.
Публикую очередное решение по резервному копированию вебсервера. Этот bash скрипт создает единый архив базы данных и всех файлов сайта. Для удобства на диске локально хранится 30 последних резервных копий. А для надежности архивы резервных копий выкладываются на облачное хранилище Яндекс.Диск.
Подобных решений полно в сети. Но данный скрипт наиболее полно отражает мое видение резервного копирования web-серверов.
Основные принципы резервного копирования
Архивы делаем встроенными средствами операционной системы, чтобы облегчить процесс создания архива и ускорить восстановление сайта на новом сервере при необходимости.
Используем форматы архивом, которые позволяют сохранить все атрибуты файлов и папок. Чтобы получить точную копию сайта на новом месте.
Отдельно архивируем со сжатием базу данных и директорию веб-сервера со всеми файлами. А потом объединяем в единый архив уже без сжатия. Имя архива для удобства формируем на основании имени домена и даты его создания.
Организуем локальное хранилище из 30-ти последний архивных копий. Чтобы была возможность «откатить» сайт в предыдущее состояние на случай непредвиденных ситуаций. К примеру при заражения вирусами. Или неудачном обновлении CMS.
Организуем независимое хранилище резервных копий в облачном хранилище Яндекс.Диск и выкладываем туда наши архивы.
BASH скрипт резервного копирования файлов сайта и базы данных MySQL
#!/bin/bash # #ver 1.0 #2013-09-09 # #Переменные Базы данных DBHOST="localhost" #Адрес MySQL сервера DBUSER="bd_user" #Имя пользователя базы данных DBPASS="dBpAsS" #Пароль пользователя базы данных DBNAME="db_name" #Имя базы данных DBARC=$DBNAME.sql.gz #Имя архива базы данных # #Переменные WEBDAV WEBDAVURL="https://webdav.yandex.ru/backup/" #Адрес Яндекс.Диск. Папка должна существовать! WEBDAVUSER="my-mail-login@yandex.ru" #Имя пользователя от Яндекс.Диска (Яндекс.Почты) WEBDAVPASS="MyPasWordAtYandexMail" #Пароль от Яндекс.Диска # #Переменные сайта SCRIPTDIR="/home/serveruser/backup/" #Абсолютный путь откуда запускается скрипт и где храняться архивы SCRDIR="/home/serveruser/web/mydomain.com/public_html/" #Абсолютный путь к сайту от корня диска SCREXCLUDE="webstat" #Что не попадет в архив SCRARC="public_html.tar.gz" #Имя архива файлов сайта # #Переменные Резерных копий ARCNAME="mydomain.com"=$(date '+%F(%H:%M)')".tar" #Имя архивной копии сайта ARCMAX="30" #Количество файлов в локальном хранилище # #Переходим в корневую директорию вебсервера cd $SCRDIR # #Создаем файловый архив со сжатием, учитываем исключения tar cfz $SCRIPTDIR$SCRARC --exclude=$SCREXCLUDE * # #Возвращаемся в папку со скриптом, где лежат все архивы cd $SCRIPTDIR # #Архивируем базу данных со сжатием mysqldump -h$DBHOST -u$DBUSER -p$DBPASS $DBNAME | gzip > $DBARC # #Объединяем файловый архив и дамп базы данных, теперь уже без сжатия tar cf $SCRIPTDIR$ARCNAME $SCRARC $DBARC # #Отправляем результат в Яндекс.Диск curl --user $WEBDAVUSER:$WEBDAVPASS -T $ARCNAME $WEBDAVURL # #Убираем промежуточные архивы rm *.gz # #Удаляем старые копии сайта, оставляем несколько свежих копий ls -t *.tar | tail -n+$ARCMAX | xargs rm -f
Теперь разберем скрипт по полочкам. С переменными указанными в начале скрипта все понятно. Я постарался максимально отделить мух от котлет и все необходимое прокомментировал.
Перейдем к исполняемой части скрипта.
Как создать архив файлов сайта
C созданием архива проблем, как правило, нет. Главное не запутаться с абсолютными и относительными путями. Чтобы быть уверенными, что вы архивируете и где сохраняете.
Чтобы избежать полных абсолютных путей в архиве предварительно перейдем в корневую директорию сайта.
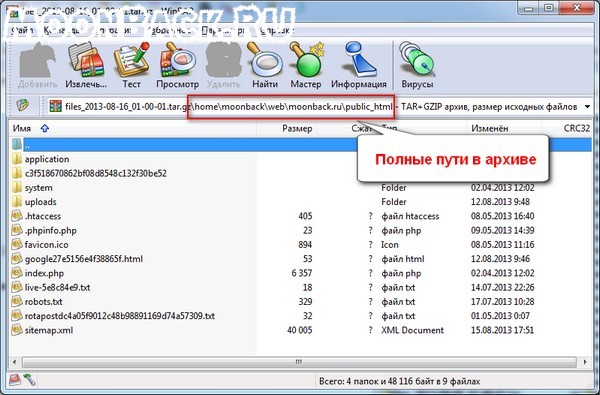
Я так не люблю, раскрываешь архив, а там папка home, заходишь в нее, а там еще одна, ты в нее, за ней следующая и так далее, короче матрешка. Замучаешься до содержимого добираться.
Поэтому перед созданием архива выполним команду:
cd $SCRDIR
Тогда в архиве будет сразу содержимое корневой директории сайта безо всяких папок и подпапок. Примерно так:
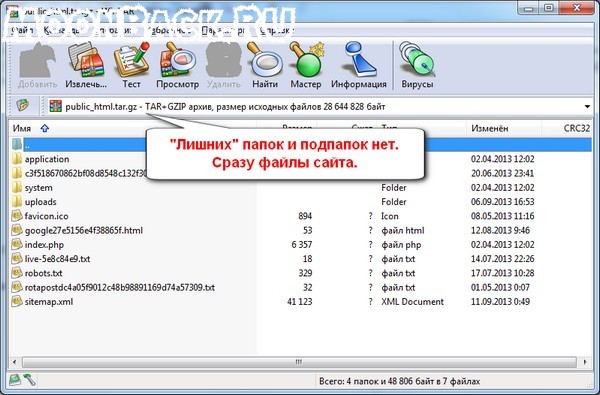
Если у Вас есть файлы, которым не обязательно быть в резервной копии сайта, у меня это папка webstat, тогда необходимо настроить параметр —exclude.
Подробнее о всех параметрах tar можно почитать в официальном мануале здесь.
Как создать резервную копию базы данных MySQL
Для получения дампа базы данных нам понадобятся параметры доступа к ней. Все они описаны в переменных скрипта и не должны вызвать затруднений. Для уменьшения размера файла сжимаем вывод утилиты mysqldump. Я использую gzip, который в *NIX-ах присутствует по-умолчанию.
Если у Вас используется старая версия MySQL сервера, до 4.1, то на базах большого объема может пригодиться параметр —quick. Использование которого указывает команде mysqldump сразу писать дамп базы на диск, а не кэшировать его в памяти. В более свежих версиях этот параметр включен по-умолчанию.
Единый файл резервных копий сайта
Чтобы решение было изящным, объединим два архива файлов сайта и дампа базы данных в один архив. Только теперь уже без сжатия, так как каждый из них мы их предварительно пропустили через gzip.
Для удобства имя файла составим из имени используемого домена и времени создания.
Как сохранить резервную копию сайта в Яндекс.Диск
В качестве облачного хранилища совсем не обязательно должен выступать Яндекс.Диск. Вы можете использовать, к примеру, Microsoft SkyDrive или любой другой сервис, использующий для доступа протокол WebDAV.
Как убрать старые копии файлов, сохранив несколько последних
В конце скрипта уберем ненужные файлы, это архивы файлов и базы данных и ограничим количество архивный копий сайта.
Осуществим поиск устаревших резервных копий и при наличии таковых их удалим. За это отвечает нижеследующий код:
ls -t *.tar | tail -n+$MAXARC | xargs rm -f
Как это работает? По команде ls ищутся архивы (файлы с расширением tar), вывод формируется по времени создания файла. Далее команда tail фильтрует список вырезая из него 30 первых. А остаток передается команде rm на удаление. Параметр f у нее служит для «молчания» в случае, если нечего удалять. Такое бывает, когда Вы только начали собирать резервные копии и их число не превышает значение переменной $MAXARC.
По совести говоря, после выполнения данной команды в «живых» останется только 29 резервных копий.
Запуск скрипта резервного копирования
Сохраняем скрипт, к примеру backup.sh. И присваиваем ему права на исполнение:
#chmod +x backup.sh
Удобнее всего использовать CRON для запуска скрипта по расписанию. Я создаю резервные копии раз в сутки в часы наименьшей нагрузки, то есть во второй половине ночи под утро.
Не забываем про владельцев папок и файлов, когда будем запускать скрипт на исполнение. Ведь файлы пользователя VASYA будут недоступны, если запустить скрипт от имени пользователя PETYA.
Результаты работы скрипта резервного копирования
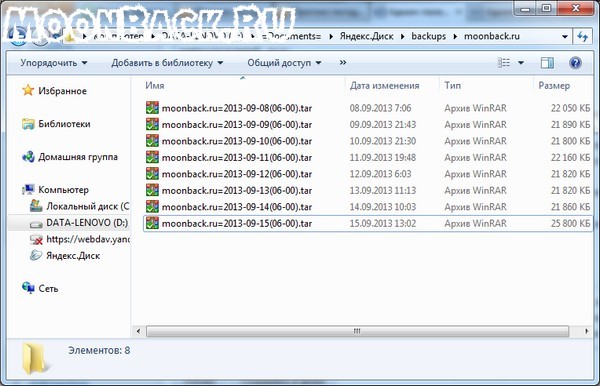
Каждый день в 6 утра на сервере создается резервная копия сайта (файлы плюс база данных) и отправляется в облачное хранилище Яндекс.Диск.
При написании статьи в качестве тестовой площадки выступал реальный сервер, на котором работает этот блог. На сервере используется CentOS 6.4 со всеми обновлениями на начало сентября 2013.
Замечания и пожелания по работе скрипта приветствуются. В планах реализовать ограничение по количеству резервных копий не только на сервере, но и в облаке Яндекс.Диск. Пока же накопившееся со временем архивы приходится вычищать вручную.